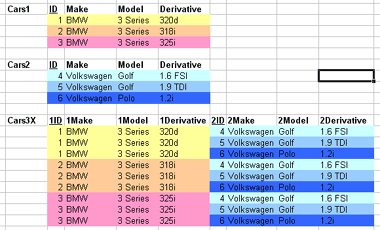
1.2.02. Relational model
- Table as relation
- Row as tuple
- real world entity or relationship
- fact
- Column as attribute
- Domain
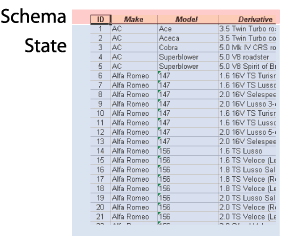
The concept of a relation is abstract, therefore we have a number of different ways of visualising it.
1.2.03. Relation
- Relation schema R(A1, A2, A3.. An)
- Design side
- Assertion/declaration
- Relation state
- Data side
- set of n-tuples
- each one an ordered list of values
- 1NF: each value is atomic, no composite/multivalue
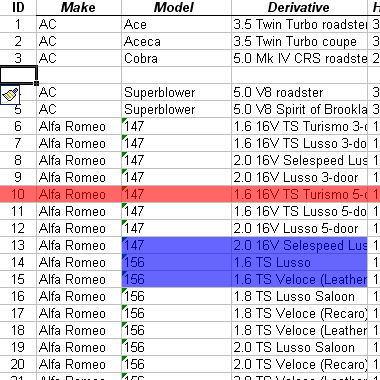
1.2.04. Abstract operations
- Database lifecycle
- design, populate, evolve
- Insert
- tuple (a1,a2,a3…an)
- Delete
- tuple (a1,a2,a3…an)
- Update (or modify)
- tuple (a1,a2,a3…an)
- attribute to change, new value
All the operations described in the next few sections are abstract. We're going to see how valuable they can be in processing real world data later.
1.2.07. Sequences of operations
- Select followed by projection
- Area clipping: rows then columns
- p<attr list>
(s(select_cond)(R)) - Rename operation (r)
- Renames attributes list2 from list1
- r(new_attr_names)(R)
1.2.08. Set Theoretic
- Binary operation: two relations
- Sets of tuples
- Union compatibility (same attributes)
- Union (R u S)
- Intersection (R n S)
- Commutative (R u (S u T) = (R u S) u T)

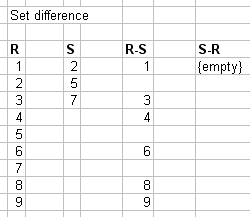
1.2.08b. Set difference
- Set difference
- Non-commutative (R-S != S-R)
1.2.09. Cross product
- Cartesian product of two relations
- R x S
- Also known as
- Cross product
- Cross join
- Cross product diagram
- Introduction to complexity
- Computationally explosive