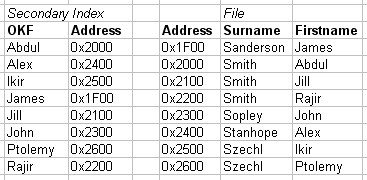
2.2.01b. Machine architecture (by distance)
- Distance from chip determines minimum latency
- Speed of light is a constant
- Impact of bus frequencies
- IDE (66,100,133 Hz)
- PCI, PCI-X (66,100,133 Hz)
- PCI Express (1Ghz to 12Ghz)
- Impact of bus bandwidths
- PCI (32/64 bit/cycle, 133MB/s)
- PCI Express (x16 8.0GB/s)
Here's a link from Intel showing a machine architecture with signal bandwidths: Intel diagram
{kind=link}
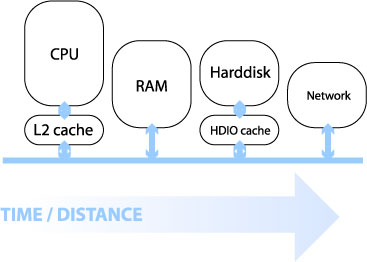
2.2.01c. Machine architecture (by capacity)
- Capacity increased with distance
- Staged architecture as compromise
- Speed, time/distance
- Also cost, heat, usage scale
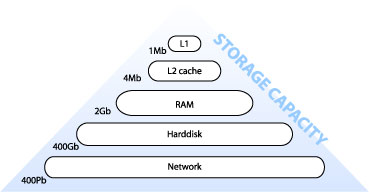
2.2.09b. Primary index example
- Primary index on simple table
- Ordering key field (primary key) is Integer
- Pointers as addresses
- Sparse, not dense
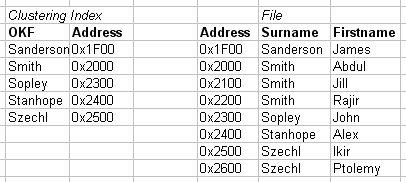
2.2.10b. Clustering index example
- Clustering index
- Ordering key field (OKF) is non-key
- Each entry points to multiple records
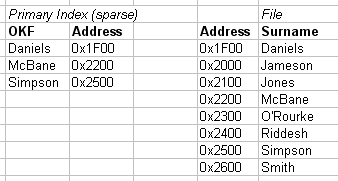
2.2.11b. Secondary Index example
- Independent of primary ordering
- Can't use block anchors
- Needs to be dense