2.1.02. Querying interfaces
- High (view) level
- Query-By-Example (QBE)
- Alternative to SQL
- Table driven (visually similar to relations)
- Rather than script driven, hence intuitive over learned
- Visual or text based
- User fills in templates
- Microsoft Access approach
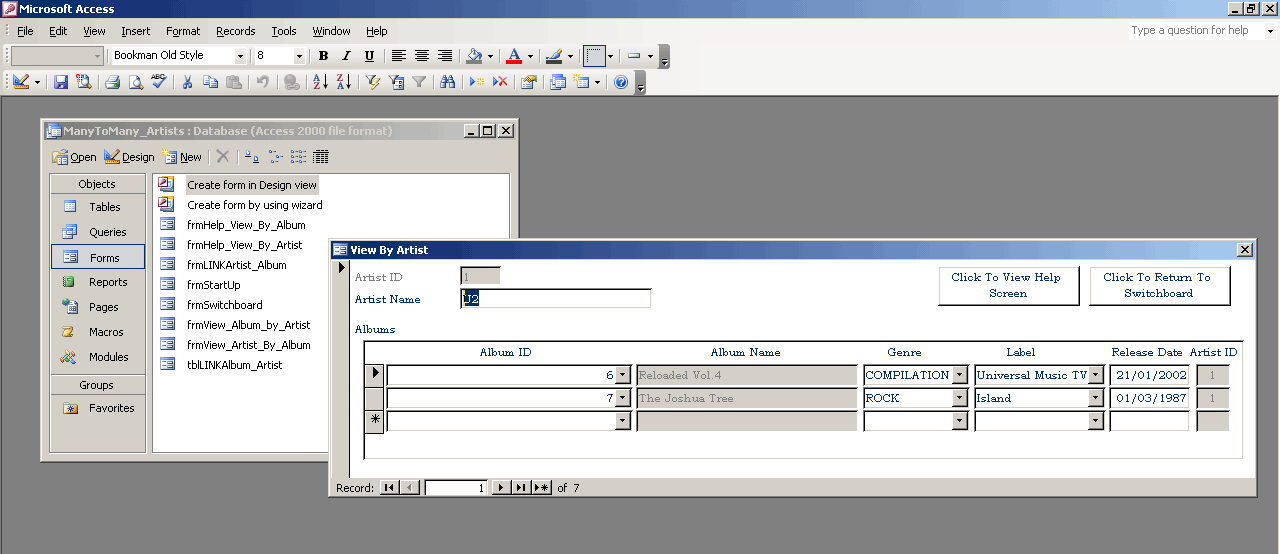
2.1.02b. QBE visual example
- Record advancing
- Query designing
- Finite domain attributes
- Web search parallel


2.1.03. QBE text-format example
- P. print, I. insert, D. delete, U. update
- _VARNAME, copy field value into variable

2.1.13. SQL Queries
- SELECT statement
- Similar to relational data model SELECT then PROJECT
- SELECT <attribute list>
- FROM <table list>
- WHERE <condition>;
2.1.18b. Outer joins
- Outer joins are crucial in the real-world
- Databases often contain NULLs (3VL)
- Analysis of where the crucial data is across a relationship
- Previous example, only get project data for managed projects
- SELECT project.*, employee.*
- FROM project INNER JOIN employee
- ON project.mgrssn = employee.ssn;
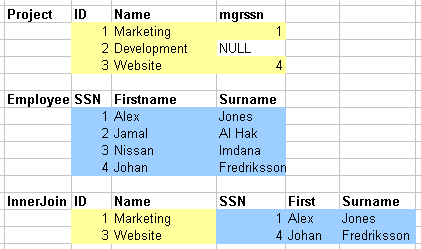
2.1.18c. Outer joins (cont)
- SELECT project.*, employee.*
- FROM project LEFT OUTER JOIN employee
- ON project.mgrssn = employee.ssn;

2.1.22. Bridging SQL across 3 tiers
- Three tier database design
- Changing role of DBMS
- Indices
- Aggregate functions (conceptual)
- Over bags and sub-bags
- Creating and updating views (ext)
- SQL embedding
In this subsection we look at the different roles SQL play across the three tiers of database design. We discuss the areas in which SQL is lacking and how those difficiencies can be complemented by embedding SQL in other languages.
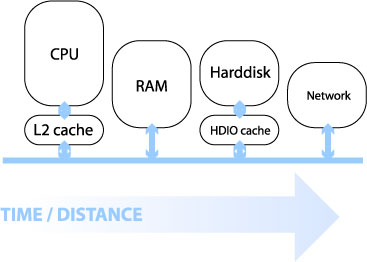
2.2.01b. Machine architecture (by distance)
- Distance from chip determines minimum latency
- Speed of light is a constant
- Impact of bus frequencies
- IDE (66,100,133 Hz)
- PCI, PCI-X (66,100,133 Hz)
- PCI Express (1Ghz to 12Ghz)
- Impact of bus bandwidths
- PCI (32/64 bit/cycle, 133MB/s)
- PCI Express (x16 8.0GB/s)
Here's a link from Intel showing a machine architecture with signal bandwidths: Intel diagram
{kind=link}
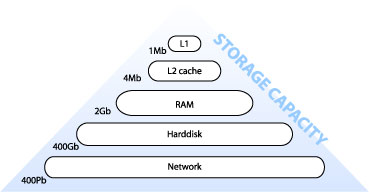
2.2.01c. Machine architecture (by capacity)
- Capacity increased with distance
- Staged architecture as compromise
- Speed, time/distance
- Also cost, heat, usage scale
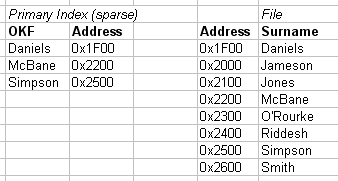
2.2.09b. Primary index example
- Primary index on simple table
- Ordering key field (primary key) is Integer
- Pointers as addresses
- Sparse, not dense
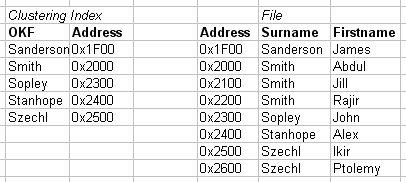
2.2.10b. Clustering index example
- Clustering index
- Ordering key field (OKF) is non-key
- Each entry points to multiple records
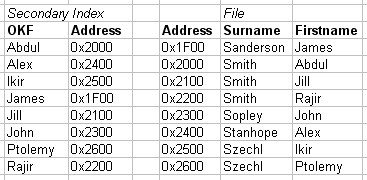
2.2.11b. Secondary Index example
- Independent of primary ordering
- Can't use block anchors
- Needs to be dense
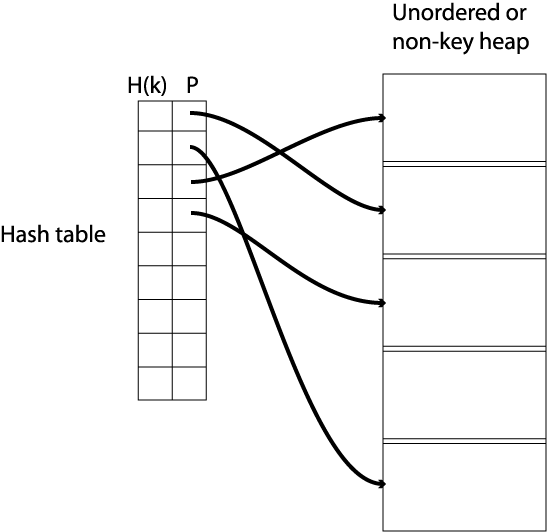
2.3.01. Hash tables
- Used to implement Indicies
- O(n) access
- Ordering Key Field (K) as argument to Hash function H()
- Address H(K) maps to pointer
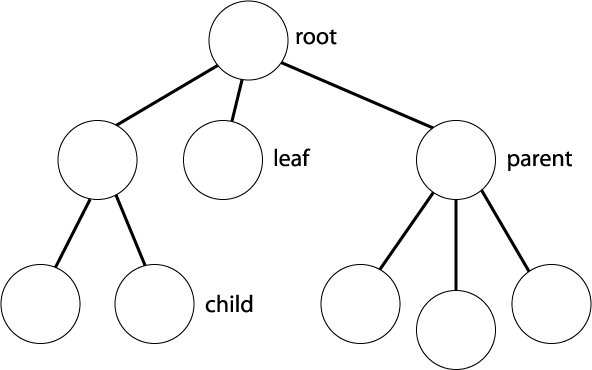
2.3.02. Tree structure
- Tree revision
- Node based
- Branching nodes/leaf nodes
- Parent/child nodes
- Root node
- Cardinality
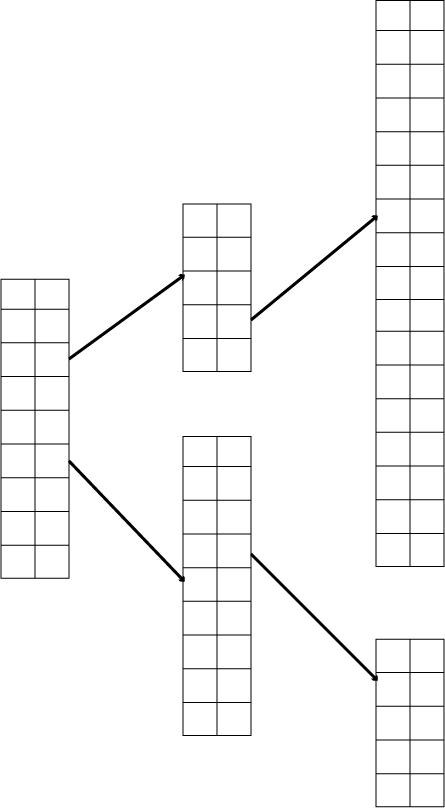
2.3.03. Multi-level indices
- Multi-level indices
- One index indexes another
- Implemented by multiple hash-tables
- <H(k),P> pairs
- (data far right)
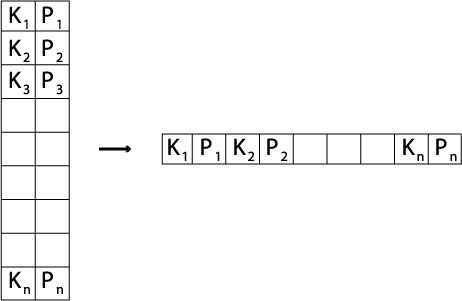
2.3.04. Index zipping
- Collapsing a single index
- Two columns become one
- <H(k),P> pairs sequentially stored
- Common in the Elmasri
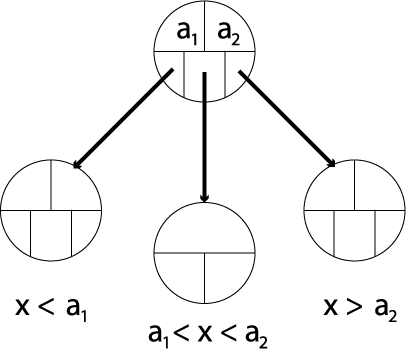
2.3.05. B-tree
- Paritioning structure
- Each node contains keys & pointers
- Pointers can be:
- Node pointers - to child nodes
- Data pointers - to records in heap
- Number of keys = Number of pointers - 1
- Every node in the tree is identical
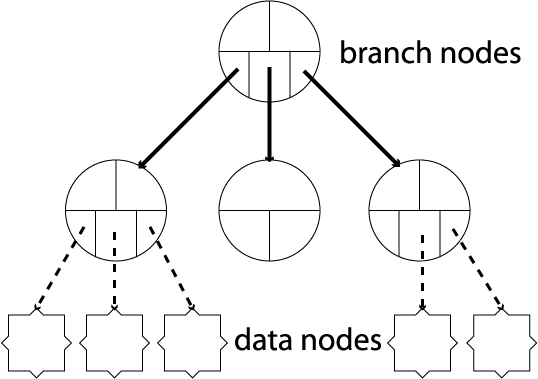
2.3.06. B+ trees
- Similar to B-trees
- Different types of nodes
- Branching nodes
- Leaf nodes
- Each branching node has:
- At most U children (max U)
- At least L children (min L)
- U = 2L, or U = 2L-1
2.3.08. B+ tree operations
- Insert operation cascades from bottom
- Rules: node can contain U children (max)
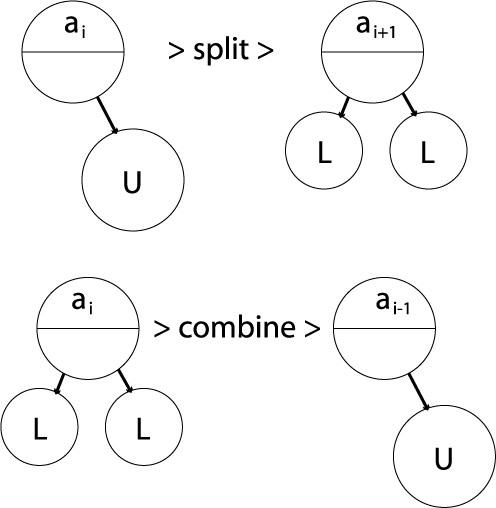
- Node combine
- Legal if child nodes contain L children
- Parent loses one key/paritition value
- Node split
- Legal if node contains U children
- Parent node gains one key/partition value
- Can cause cascade up tree & rebalancing