2.1.02. Querying interfaces
- High (view) level
- Query-By-Example (QBE)
- Alternative to SQL
- Table driven (visually similar to relations)
- Rather than script driven, hence intuitive over learned
- Visual or text based
- User fills in templates
- Microsoft Access approach
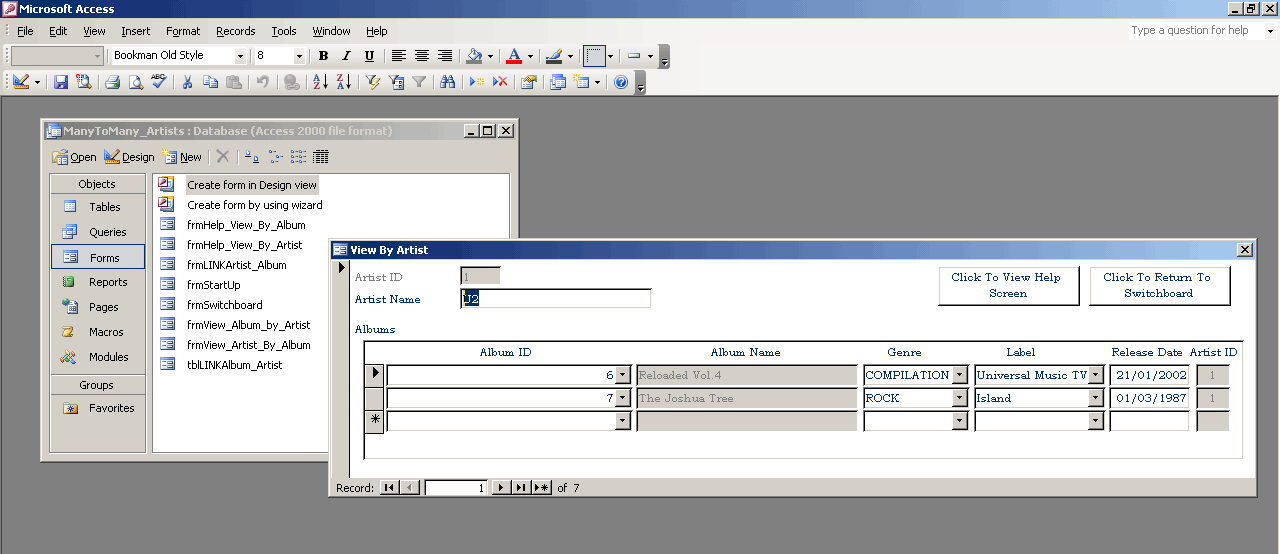
2.1.02b. QBE visual example
- Record advancing
- Query designing
- Finite domain attributes
- Web search parallel


2.1.03. QBE text-format example
- P. print, I. insert, D. delete, U. update
- _VARNAME, copy field value into variable

2.1.13. SQL Queries
- SELECT statement
- Similar to relational data model SELECT then PROJECT
- SELECT <attribute list>
- FROM <table list>
- WHERE <condition>;
2.1.18b. Outer joins
- Outer joins are crucial in the real-world
- Databases often contain NULLs (3VL)
- Analysis of where the crucial data is across a relationship
- Previous example, only get project data for managed projects
- SELECT project.*, employee.*
- FROM project INNER JOIN employee
- ON project.mgrssn = employee.ssn;
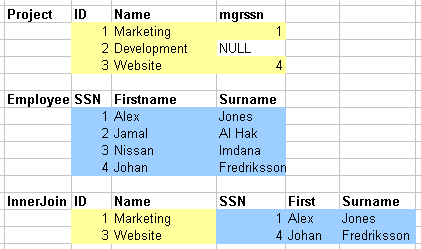
2.1.18c. Outer joins (cont)
- SELECT project.*, employee.*
- FROM project LEFT OUTER JOIN employee
- ON project.mgrssn = employee.ssn;

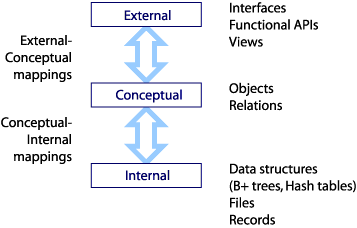
2.1.22. Bridging SQL across 3 tiers
- Three tier database design
- Changing role of DBMS
- Indices
- Aggregate functions (conceptual)
- Over bags and sub-bags
- Creating and updating views (ext)
- SQL embedding
In this subsection we look at the different roles SQL play across the three tiers of database design. We discuss the areas in which SQL is lacking and how those difficiencies can be complemented by embedding SQL in other languages.