5.2.06. DB Company organisation
- By example
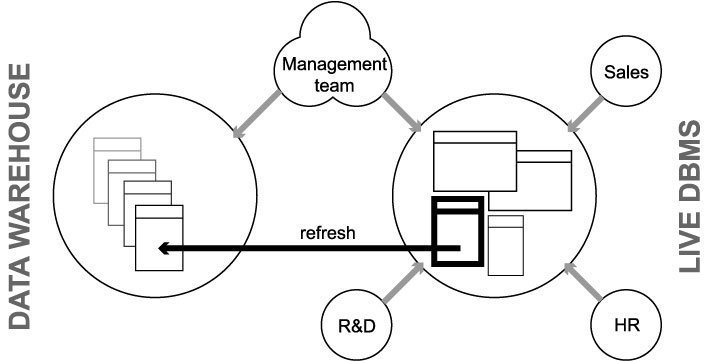
5.2.08. Star schemae and Hypercubes
- Data centralised in ‘fact’ table
- Referencing creates star pattern
- Dimensions as satellite tables
- Normalising creates snowflake schema
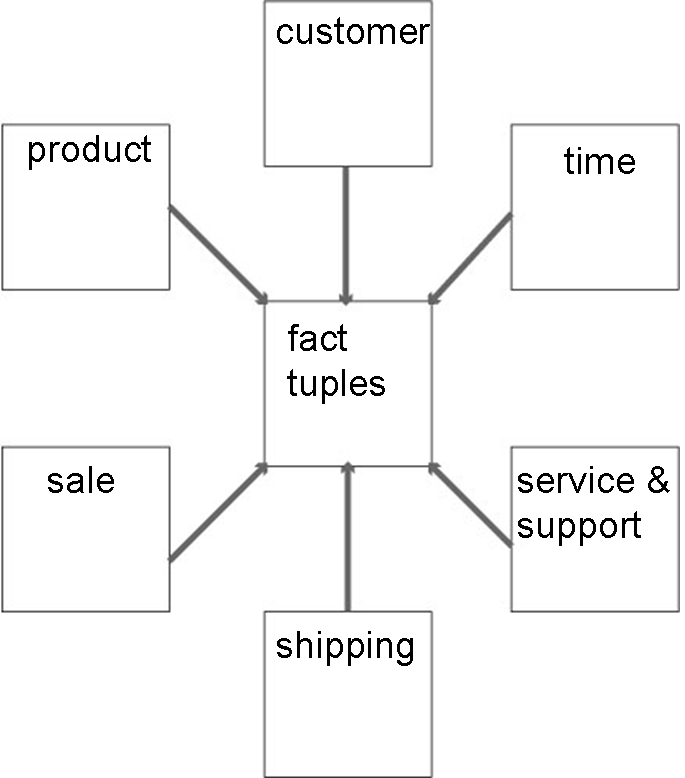
5.2.09. Hypercubes
- Hypercube is also a multi-processor topology inspired by a 4D shape
- Used by Intel’s iPSC/2
- Good at certain database operations
- e.g. Duplicate removal
- MIMD