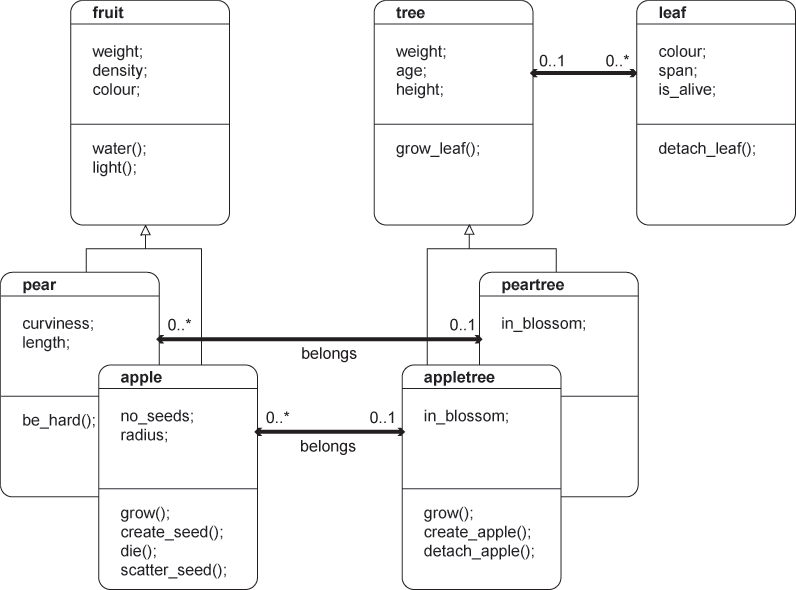
1.1.06. Data-design divide
- Left-hand/right-hand divide
- LHS: Catalog
- or Meta-data
- or Intension
- or Schema
- i.e. the Design of database
- Types of data, organisation, constraints
- RHS: Extension
- or Snapshot
- The data itself
- Information stored in the database
- Tuples
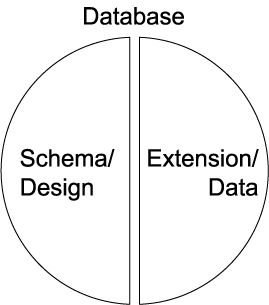
1.1.14. Logical and physical program-data independence
- Three tier data-model diagram
- Mappings, Data independence
- Logical
- between conceptual and external
- changes to conceptual without changing
- external schemas or application programs
- Physical
- between internal and conceptual
- changes to internal without changing
- conceptual or external schemas
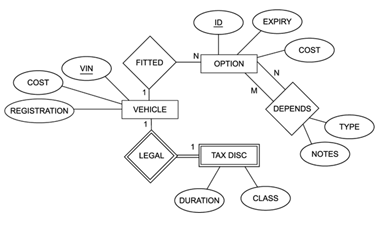
1.1.18. Design side
- Meta-data
- Database schema, intension
- Data Model
- Left hand side of database divide
- Schema diagram
- Entity-relationship (ER diagrams)
- UML diagrams
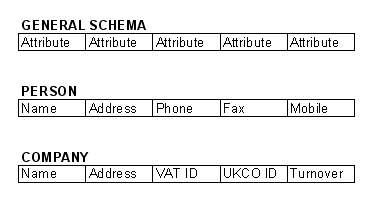
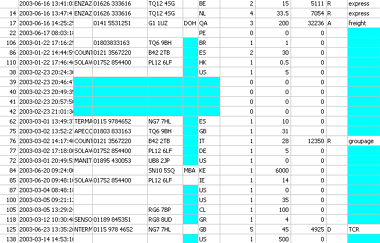
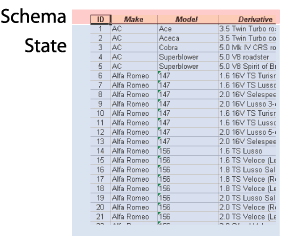
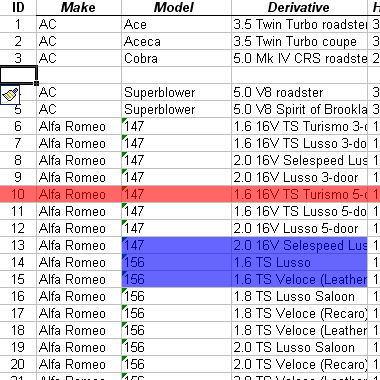
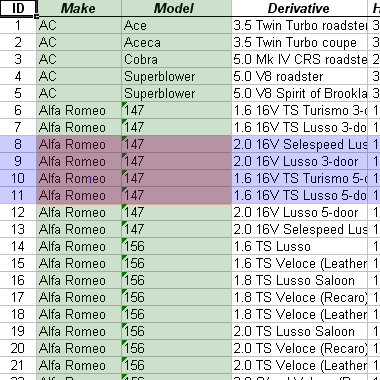
1.1.19. Data side
- Data, under the column heading
- Less easy to look at (volume issue)
- Fundamentally less interesting (more specific)
- Variety of tools for looking at it:
- Here's what a snapshot looks like:
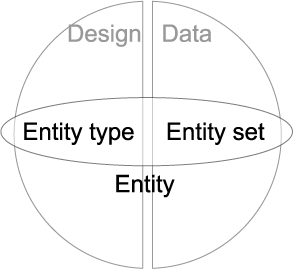
1.1.21. Entity
- Selected from real world
- Populate Miniworld/UoD
- Entity is an approximation
- Two elements: Entity types and sets
- Collection of attributes
- Object similarity, classes as entity types
- Entities inter-relate
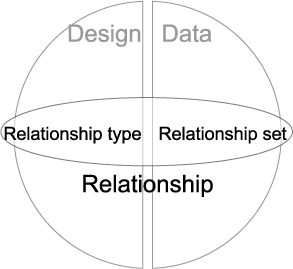
1.1.27. Relationships
- Types and Sets
- Participation by Entities
- Degree - e.g. binary
- Cardinality ratios - e.g. 1:1, 1:M
- Determine occurrence
- Tuples example
- Foreign keys
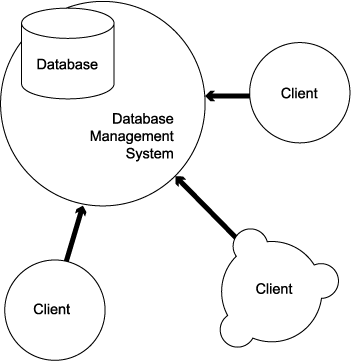
1.1.28. Database architecture
- Client-Server
- Distributed databases
- Fragmentation by attribute/tuple/relation
- Language and description
- Storage Definition Language (SDL) DESIGN
- Data Definition Language (DDL) DESIGN
- View Definition Language (VDL) DESIGN
- Data Manipulation Language (DML) DATA
- High level, can be embedded but precompiled
- Procedural, record-at-a-time, requires high level support
1.2.02. Relational model
- Table as relation
- Row as tuple
- real world entity or relationship
- fact
- Column as attribute
- Domain
The concept of a relation is abstract, therefore we have a number of different ways of visualising it.
1.2.03. Relation
- Relation schema R(A1, A2, A3.. An)
- Design side
- Assertion/declaration
- Relation state
- Data side
- set of n-tuples
- each one an ordered list of values
- 1NF: each value is atomic, no composite/multivalue
1.2.04. Abstract operations
- Database lifecycle
- design, populate, evolve
- Insert
- tuple (a1,a2,a3…an)
- Delete
- tuple (a1,a2,a3…an)
- Update (or modify)
- tuple (a1,a2,a3…an)
- attribute to change, new value
All the operations described in the next few sections are abstract. We're going to see how valuable they can be in processing real world data later.
1.2.07. Sequences of operations
- Select followed by projection
- Area clipping: rows then columns
- p<attr list>
(s(select_cond)(R)) - Rename operation (r)
- Renames attributes list2 from list1
- r(new_attr_names)(R)
1.2.08. Set Theoretic
- Binary operation: two relations
- Sets of tuples
- Union compatibility (same attributes)
- Union (R u S)
- Intersection (R n S)
- Commutative (R u (S u T) = (R u S) u T)

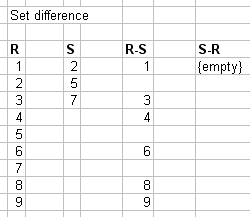
1.2.08b. Set difference
- Set difference
- Non-commutative (R-S != S-R)
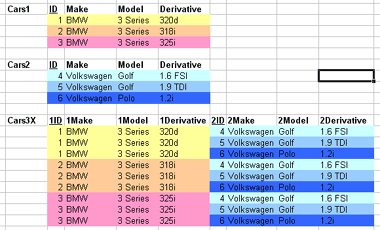
1.2.09. Cross product
- Cartesian product of two relations
- R x S
- Also known as
- Cross product
- Cross join
- Cross product diagram
- Introduction to complexity
- Computationally explosive
1.3.04. Pointing mechanism
- Relation has a Primary key
- Tuple contains Primary key value
- Foreign keys
- Tuples can contain a reference to another relation's Primary key
- Just numbers
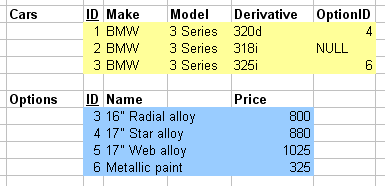
One number identifies a single tuple in one relation (local), one number identifies a single tuple in another relation (foreign).
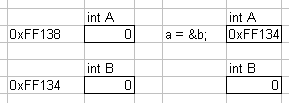
1.3.04b. Pointing mechanism example in C
- C programming language
- Memory addresses, or pointers
int a=0; int b=0; a = &b;
- a points to b
In databases, typically done with unique identifiers (IDs) rather than memory addresses.
1.3.04c. Pointing mechanism with structures
- Foreign key importing
typedef struct car { int ID; char[] make; char[] model; char[] derivative; int optionID; } car; typedef struct option { int ID; char[] name; int price; } option; car c; option o; //...data structure populating c.optionID = o.ID;
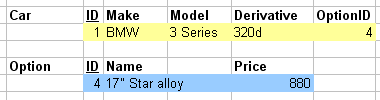
1.3.06. Relationships in the relational model
- Two relations, A and B
- A side, B side, 1 side, N side
- 1:1 relationships
- Key can go on either side
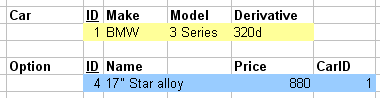
- 1:N relationships
- Key cannot go on 1 side
- Has to go on N side

- M:N relationships
- Nowhere obvious for the key to go
- Create new pairing relation
1.3.10. Join types (condition)
- Theta: Ai q Bj
(A from R, B from S) - q is comparison operator
=,<,>,!=,>= - Ai and Bj share the same domain
- Equi: Ai = Bj
- Theta join where q is =
- Natural: Ai and Bj are the same attribute
- in two separate relations (name and domain)
- * denotes natural join
- e.g. EMPNAMES * DEPENDENTS
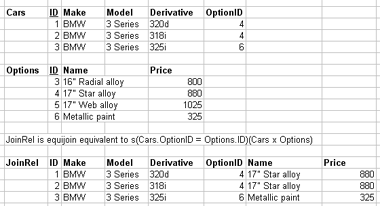
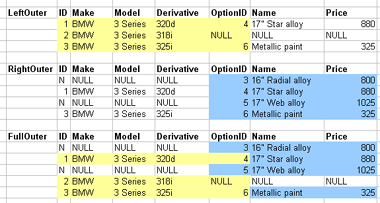
1.3.11. Join types (inner and outer)
- Inner joins
- not the only joins
- eliminate tuples without a matching counterpart
- i.e. tuples with a null value for the join attribute are discarded
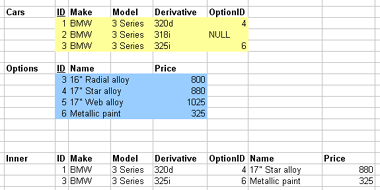
1.3.12. Outer joins
- Outer joins control what's discarded
- Keep unmatched tuples in either
- Left, right, or both relations
- Left, right of full outer join correspondingly
1.4.04. Database Left:right divide
- Design
- Catalog, Meta-data, Intension, or Database schema
- Entity type
- Relationship type
- State
- Set of occurences/instances, Extension, snapshot
- Entity set
- Relationship set
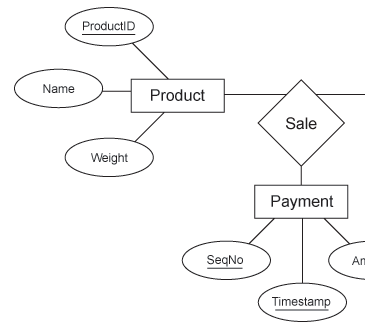
1.4.05. Basic ER diagram
- Typically part of a system
- (Strong) Entities
- Product
- Customer
- Payment
- Relationships
- Sale
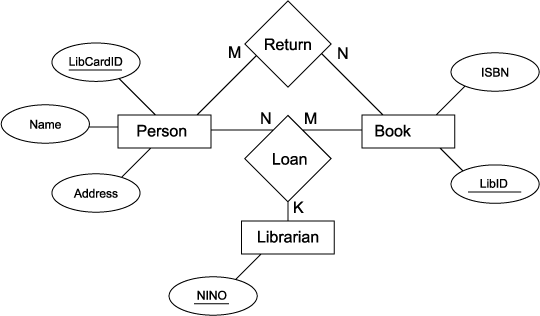
1.4.11. Library example
- Library example
- Entities: Person, Book, Librarian
- Time-perspective implications
1.5.01. UML diagrams
- Not just one type of diagram
- ER Entities -> UML objects
- Adds scope to include methods

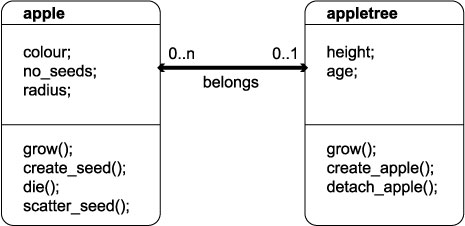
1.5.03. Simple UML relationship diagram
- Classes
- Attributes
- Methods
- Relationships
- Participation
- Cardinality
- Roles
1.5.04. UML inheritance
- Notion of inheritance
- Java parallel
- 'is a' relationships
- Database Student
- is a Computer Science Student
- is an Engineering Faculty Student
-
- is a Student
- is a Person
- Inheritance hierarchies
- UML diagrams can be used to show inheritance
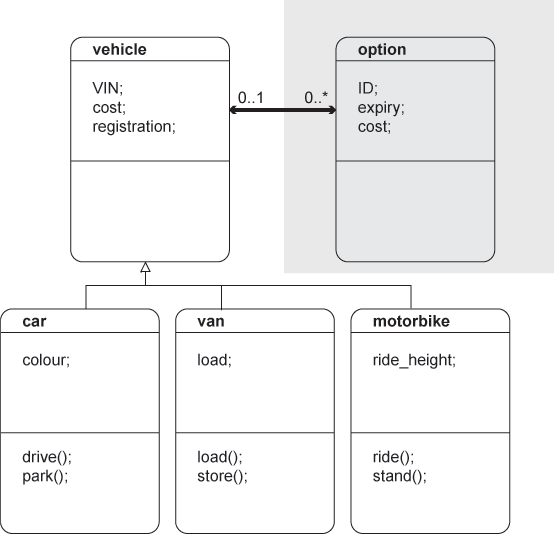
1.5.05. UML diagram
- Classes
- Relationships
- Inheritance