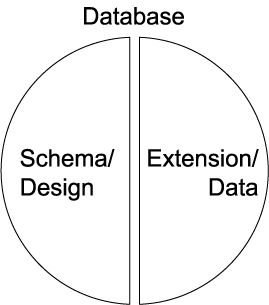
1.1.06. Data-design divide
- Left-hand/right-hand divide
- LHS: Catalog
- or Meta-data
- or Intension
- or Schema
- i.e. the Design of database
- Types of data, organisation, constraints
- RHS: Extension
- or Snapshot
- The data itself
- Information stored in the database
- Tuples
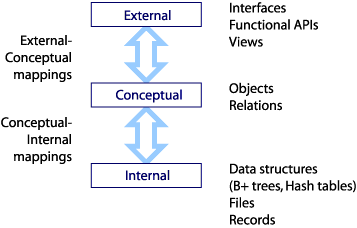
1.1.14. Logical and physical program-data independence
- Three tier data-model diagram
- Mappings, Data independence
- Logical
- between conceptual and external
- changes to conceptual without changing
- external schemas or application programs
- Physical
- between internal and conceptual
- changes to internal without changing
- conceptual or external schemas
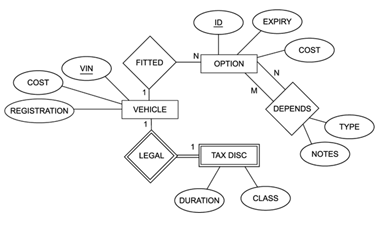
1.1.18. Design side
- Meta-data
- Database schema, intension
- Data Model
- Left hand side of database divide
- Schema diagram
- Entity-relationship (ER diagrams)
- UML diagrams
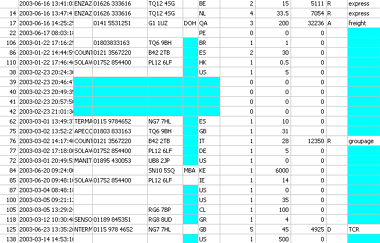
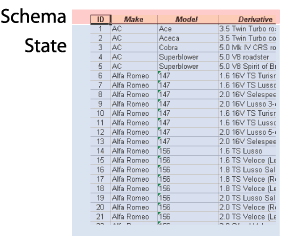
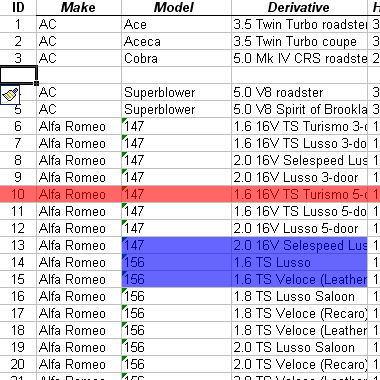
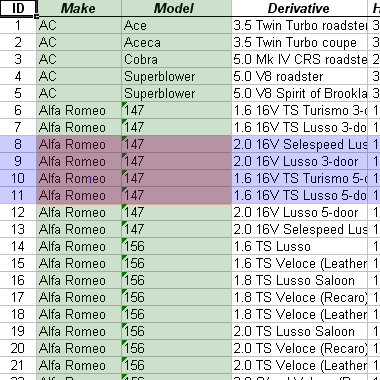
1.1.19. Data side
- Data, under the column heading
- Less easy to look at (volume issue)
- Fundamentally less interesting (more specific)
- Variety of tools for looking at it:
- Here's what a snapshot looks like:
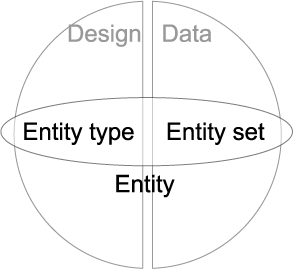
1.1.21. Entity
- Selected from real world
- Populate Miniworld/UoD
- Entity is an approximation
- Two elements: Entity types and sets
- Collection of attributes
- Object similarity, classes as entity types
- Entities inter-relate
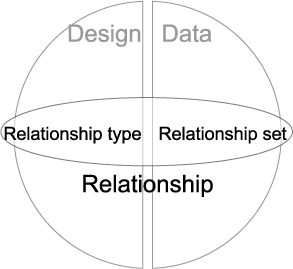
1.1.27. Relationships
- Types and Sets
- Participation by Entities
- Degree - e.g. binary
- Cardinality ratios - e.g. 1:1, 1:M
- Determine occurrence
- Tuples example
- Foreign keys
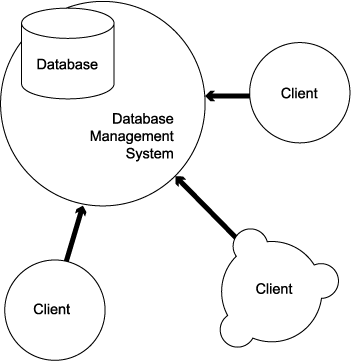
1.1.28. Database architecture
- Client-Server
- Distributed databases
- Fragmentation by attribute/tuple/relation
- Language and description
- Storage Definition Language (SDL) DESIGN
- Data Definition Language (DDL) DESIGN
- View Definition Language (VDL) DESIGN
- Data Manipulation Language (DML) DATA
- High level, can be embedded but precompiled
- Procedural, record-at-a-time, requires high level support
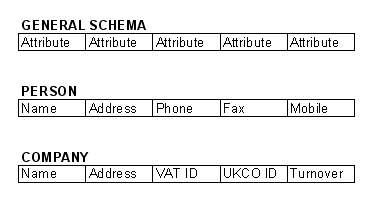
1.2.02. Relational model
- Table as relation
- Row as tuple
- real world entity or relationship
- fact
- Column as attribute
- Domain
The concept of a relation is abstract, therefore we have a number of different ways of visualising it.
1.2.03. Relation
- Relation schema R(A1, A2, A3.. An)
- Design side
- Assertion/declaration
- Relation state
- Data side
- set of n-tuples
- each one an ordered list of values
- 1NF: each value is atomic, no composite/multivalue
1.2.04. Abstract operations
- Database lifecycle
- design, populate, evolve
- Insert
- tuple (a1,a2,a3…an)
- Delete
- tuple (a1,a2,a3…an)
- Update (or modify)
- tuple (a1,a2,a3…an)
- attribute to change, new value
All the operations described in the next few sections are abstract. We're going to see how valuable they can be in processing real world data later.
1.2.07. Sequences of operations
- Select followed by projection
- Area clipping: rows then columns
- p<attr list>
(s(select_cond)(R)) - Rename operation (r)
- Renames attributes list2 from list1
- r(new_attr_names)(R)
1.2.08. Set Theoretic
- Binary operation: two relations
- Sets of tuples
- Union compatibility (same attributes)
- Union (R u S)
- Intersection (R n S)
- Commutative (R u (S u T) = (R u S) u T)

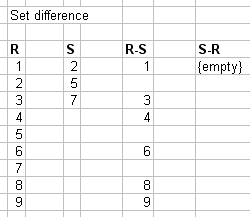
1.2.08b. Set difference
- Set difference
- Non-commutative (R-S != S-R)
1.2.09. Cross product
- Cartesian product of two relations
- R x S
- Also known as
- Cross product
- Cross join
- Cross product diagram
- Introduction to complexity
- Computationally explosive
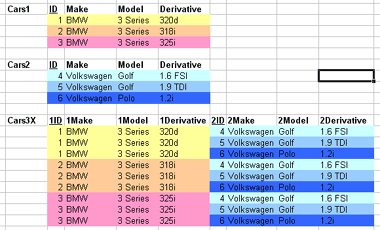
1.3.04. Pointing mechanism
- Relation has a Primary key
- Tuple contains Primary key value
- Foreign keys
- Tuples can contain a reference to another relation's Primary key
- Just numbers
One number identifies a single tuple in one relation (local), one number identifies a single tuple in another relation (foreign).
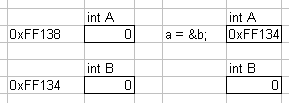
1.3.04b. Pointing mechanism example in C
- C programming language
- Memory addresses, or pointers
int a=0; int b=0; a = &b;
- a points to b
In databases, typically done with unique identifiers (IDs) rather than memory addresses.
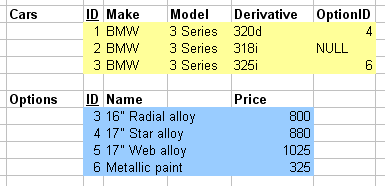
1.3.04c. Pointing mechanism with structures
- Foreign key importing
typedef struct car { int ID; char[] make; char[] model; char[] derivative; int optionID; } car; typedef struct option { int ID; char[] name; int price; } option; car c; option o; //...data structure populating c.optionID = o.ID;
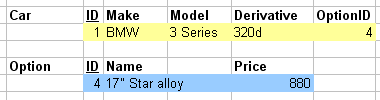
1.3.06. Relationships in the relational model
- Two relations, A and B
- A side, B side, 1 side, N side
- 1:1 relationships
- Key can go on either side
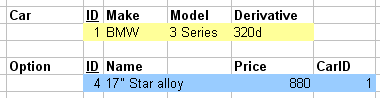
- 1:N relationships
- Key cannot go on 1 side
- Has to go on N side

- M:N relationships
- Nowhere obvious for the key to go
- Create new pairing relation
1.3.10. Join types (condition)
- Theta: Ai q Bj
(A from R, B from S) - q is comparison operator
=,<,>,!=,>= - Ai and Bj share the same domain
- Equi: Ai = Bj
- Theta join where q is =
- Natural: Ai and Bj are the same attribute
- in two separate relations (name and domain)
- * denotes natural join
- e.g. EMPNAMES * DEPENDENTS
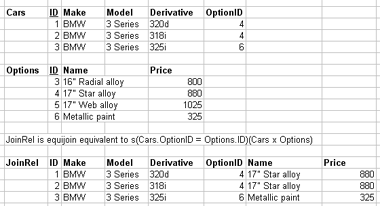
1.3.11. Join types (inner and outer)
- Inner joins
- not the only joins
- eliminate tuples without a matching counterpart
- i.e. tuples with a null value for the join attribute are discarded
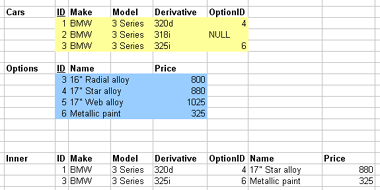
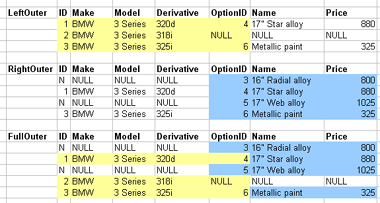
1.3.12. Outer joins
- Outer joins control what's discarded
- Keep unmatched tuples in either
- Left, right, or both relations
- Left, right of full outer join correspondingly
1.4.04. Database Left:right divide
- Design
- Catalog, Meta-data, Intension, or Database schema
- Entity type
- Relationship type
- State
- Set of occurences/instances, Extension, snapshot
- Entity set
- Relationship set
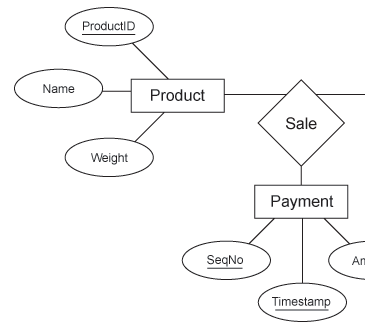
1.4.05. Basic ER diagram
- Typically part of a system
- (Strong) Entities
- Product
- Customer
- Payment
- Relationships
- Sale
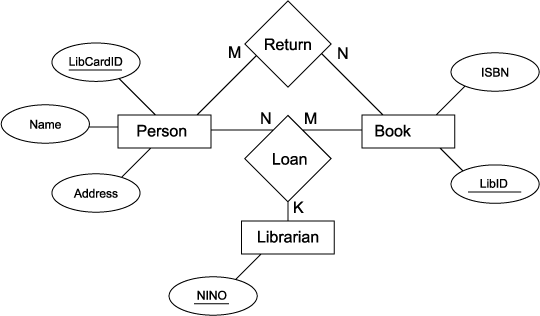
1.4.11. Library example
- Library example
- Entities: Person, Book, Librarian
- Time-perspective implications
1.5.01. UML diagrams
- Not just one type of diagram
- ER Entities -> UML objects
- Adds scope to include methods

1.5.03. Simple UML relationship diagram
- Classes
- Attributes
- Methods
- Relationships
- Participation
- Cardinality
- Roles
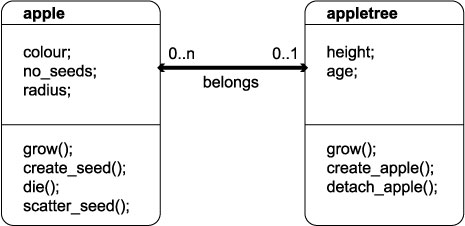
1.5.04. UML inheritance
- Notion of inheritance
- Java parallel
- 'is a' relationships
- Database Student
- is a Computer Science Student
- is an Engineering Faculty Student
-
- is a Student
- is a Person
- Inheritance hierarchies
- UML diagrams can be used to show inheritance
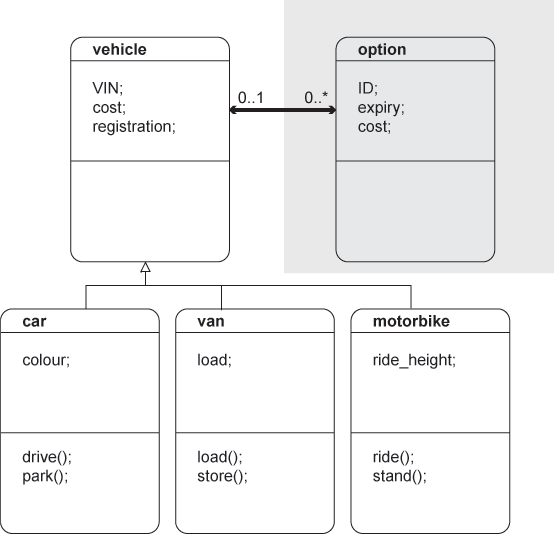
1.5.05. UML diagram
- Classes
- Relationships
- Inheritance
2.1.02. Querying interfaces
- High (view) level
- Query-By-Example (QBE)
- Alternative to SQL
- Table driven (visually similar to relations)
- Rather than script driven, hence intuitive over learned
- Visual or text based
- User fills in templates
- Microsoft Access approach
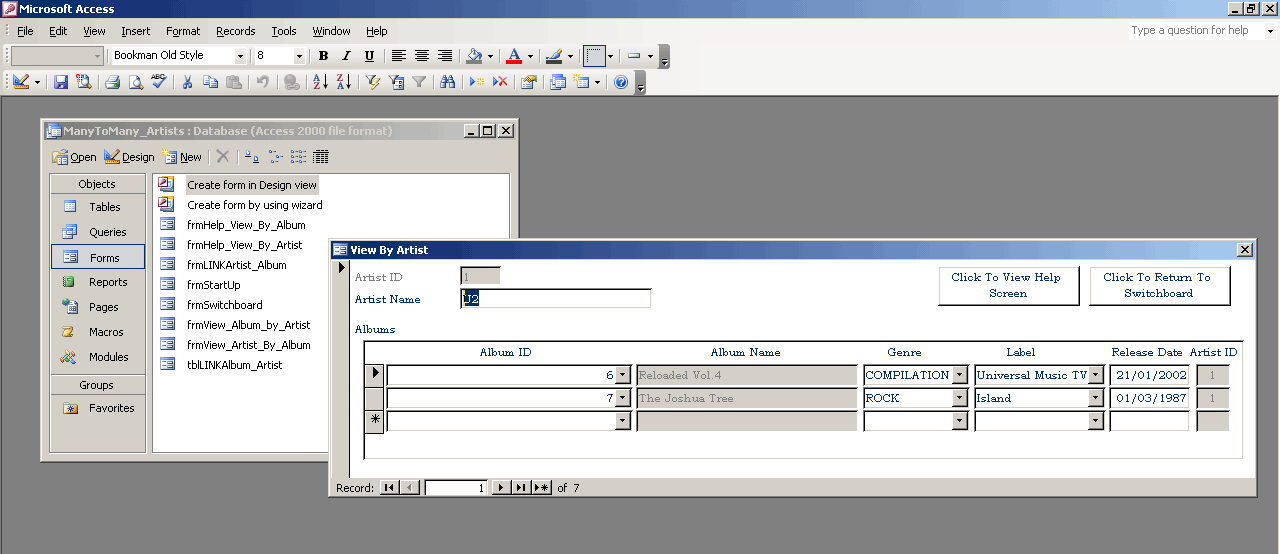
2.1.02b. QBE visual example
- Record advancing
- Query designing
- Finite domain attributes
- Web search parallel


2.1.03. QBE text-format example
- P. print, I. insert, D. delete, U. update
- _VARNAME, copy field value into variable

2.1.13. SQL Queries
- SELECT statement
- Similar to relational data model SELECT then PROJECT
- SELECT <attribute list>
- FROM <table list>
- WHERE <condition>;
2.1.18b. Outer joins
- Outer joins are crucial in the real-world
- Databases often contain NULLs (3VL)
- Analysis of where the crucial data is across a relationship
- Previous example, only get project data for managed projects
- SELECT project.*, employee.*
- FROM project INNER JOIN employee
- ON project.mgrssn = employee.ssn;
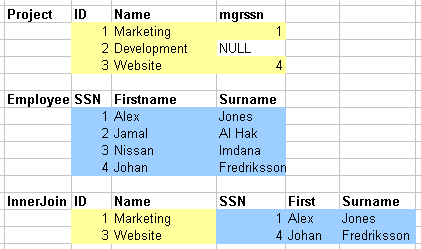
2.1.18c. Outer joins (cont)
- SELECT project.*, employee.*
- FROM project LEFT OUTER JOIN employee
- ON project.mgrssn = employee.ssn;

2.1.22. Bridging SQL across 3 tiers
- Three tier database design
- Changing role of DBMS
- Indices
- Aggregate functions (conceptual)
- Over bags and sub-bags
- Creating and updating views (ext)
- SQL embedding
In this subsection we look at the different roles SQL play across the three tiers of database design. We discuss the areas in which SQL is lacking and how those difficiencies can be complemented by embedding SQL in other languages.
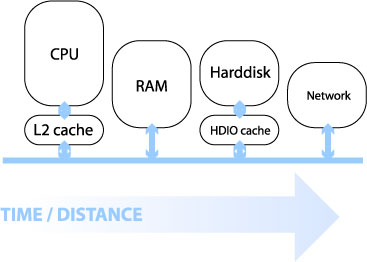
2.2.01b. Machine architecture (by distance)
- Distance from chip determines minimum latency
- Speed of light is a constant
- Impact of bus frequencies
- IDE (66,100,133 Hz)
- PCI, PCI-X (66,100,133 Hz)
- PCI Express (1Ghz to 12Ghz)
- Impact of bus bandwidths
- PCI (32/64 bit/cycle, 133MB/s)
- PCI Express (x16 8.0GB/s)
Here's a link from Intel showing a machine architecture with signal bandwidths: Intel diagram
{kind=link}
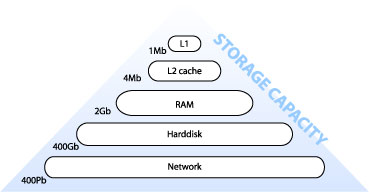
2.2.01c. Machine architecture (by capacity)
- Capacity increased with distance
- Staged architecture as compromise
- Speed, time/distance
- Also cost, heat, usage scale
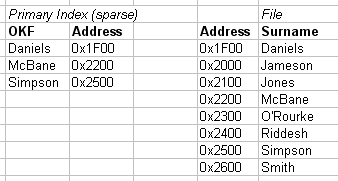
2.2.09b. Primary index example
- Primary index on simple table
- Ordering key field (primary key) is Integer
- Pointers as addresses
- Sparse, not dense
2.2.10b. Clustering index example
- Clustering index
- Ordering key field (OKF) is non-key
- Each entry points to multiple records
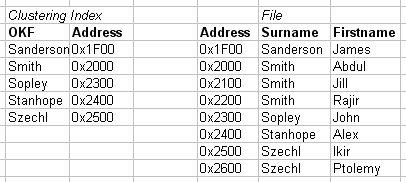
2.2.11b. Secondary Index example
- Independent of primary ordering
- Can't use block anchors
- Needs to be dense
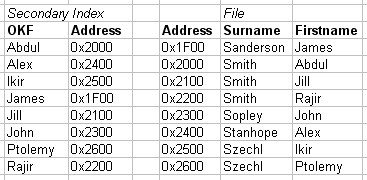
2.3.01. Hash tables
- Used to implement Indicies
- O(n) access
- Ordering Key Field (K) as argument to Hash function H()
- Address H(K) maps to pointer
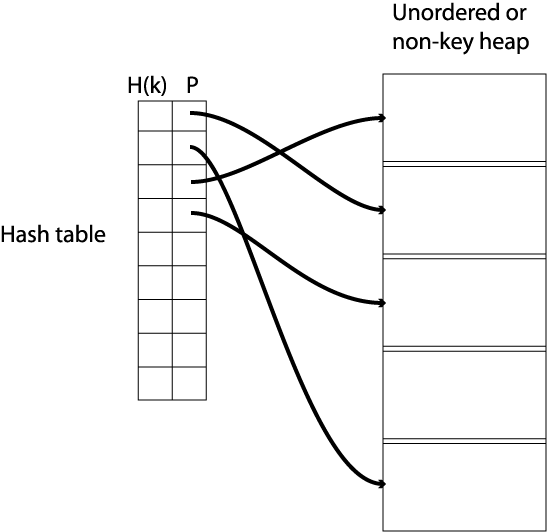
2.3.02. Tree structure
- Tree revision
- Node based
- Branching nodes/leaf nodes
- Parent/child nodes
- Root node
- Cardinality
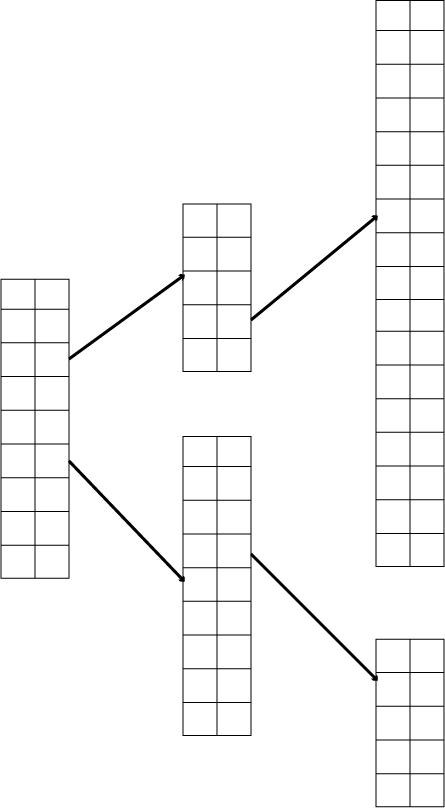
2.3.03. Multi-level indices
- Multi-level indices
- One index indexes another
- Implemented by multiple hash-tables
- <H(k),P> pairs
- (data far right)
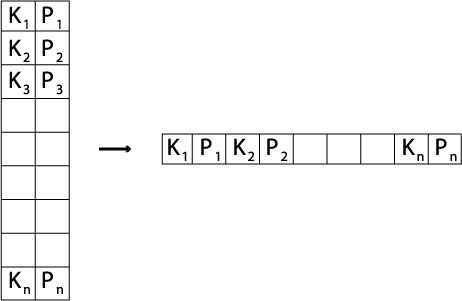
2.3.04. Index zipping
- Collapsing a single index
- Two columns become one
- <H(k),P> pairs sequentially stored
- Common in the Elmasri
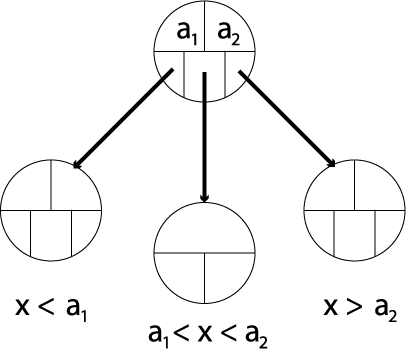
2.3.05. B-tree
- Paritioning structure
- Each node contains keys & pointers
- Pointers can be:
- Node pointers - to child nodes
- Data pointers - to records in heap
- Number of keys = Number of pointers - 1
- Every node in the tree is identical
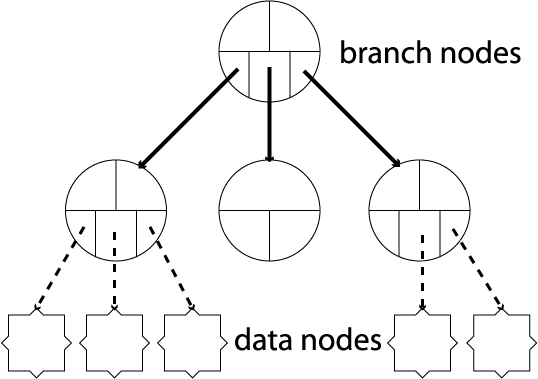
2.3.06. B+ trees
- Similar to B-trees
- Different types of nodes
- Branching nodes
- Leaf nodes
- Each branching node has:
- At most U children (max U)
- At least L children (min L)
- U = 2L, or U = 2L-1
2.3.08. B+ tree operations
- Insert operation cascades from bottom
- Rules: node can contain U children (max)
- Node combine
- Legal if child nodes contain L children
- Parent loses one key/paritition value
- Node split
- Legal if node contains U children
- Parent node gains one key/partition value
- Can cause cascade up tree & rebalancing
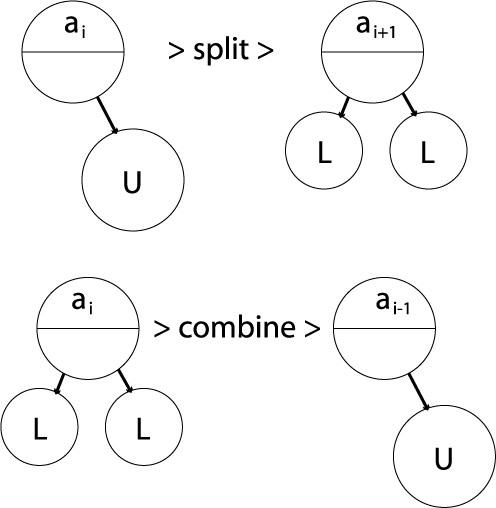
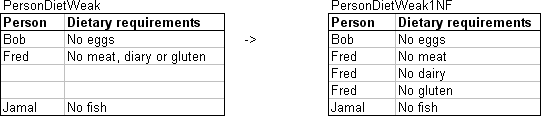
3.2.06. Normalisation (1NF)
- On weak entity
- On strong entity
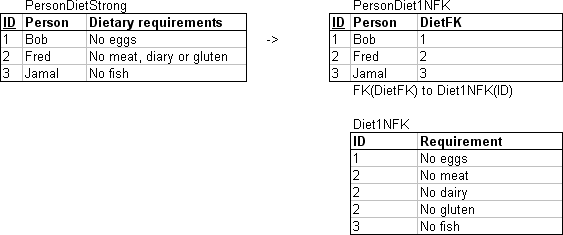
3.2.10. Normalisation (2NF)
- Split attributes not depended on all of the primary key into separate relations

3.2.14. Normalisation (3NF)
- CarMakes not in 3NF because:
- singleton key A
- non-trivial fd B → C
- B not superkey, C not prime attribute

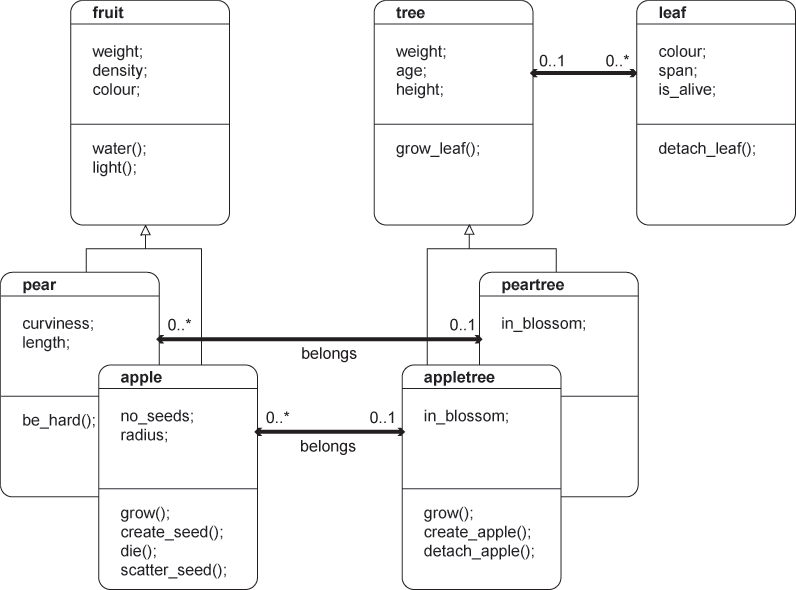
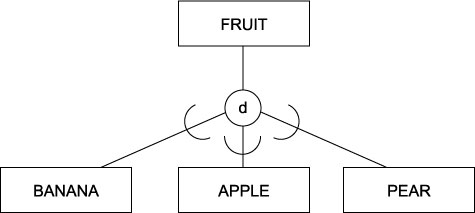
3.4.07. EER Fruit example
- Partial participation
- Disjoint subclasses
- A fruit may be either a pear or an apple or a banana, or none of them. A fruit may not be a pear and a banana, an apple and a banana, an apple and a pear …
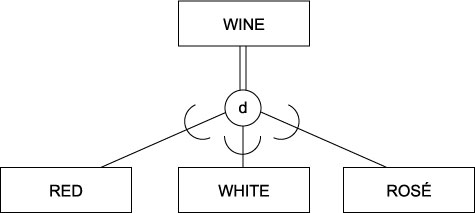
3.4.08. EER Wine example
- Total, disjoint
- Equivalent to Java Abstract classes
- A Wine has to be either Red, White or Rosé cannot be both more
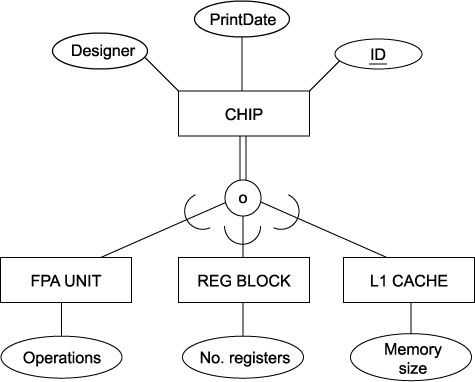
3.4.13. EER Chip example
- Total, overlapping
- A Chip may has to be at least one of FPA Unit, Reg Block, L1 Cache, and may be more than one type
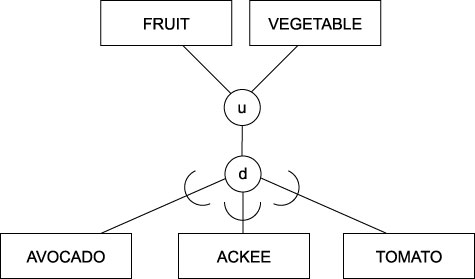
3.4.14. EER Multiple inheritance
- Type hierarchies
- Specialisation lattices
- Well, sir, the Supreme Court of the United States has determined that the tomato is for legal and commercial purposes both a fruit and a vegetable. So we can legally refer to tomato juice as 'vegetable' juice.
- Candice, General Foods
3.5.04. Quality paradigm
- Large projects require large teams
- Team overhead (ref 2nd year)
- Code responsibilities
- Data/data model resp.
- Object responsibilities
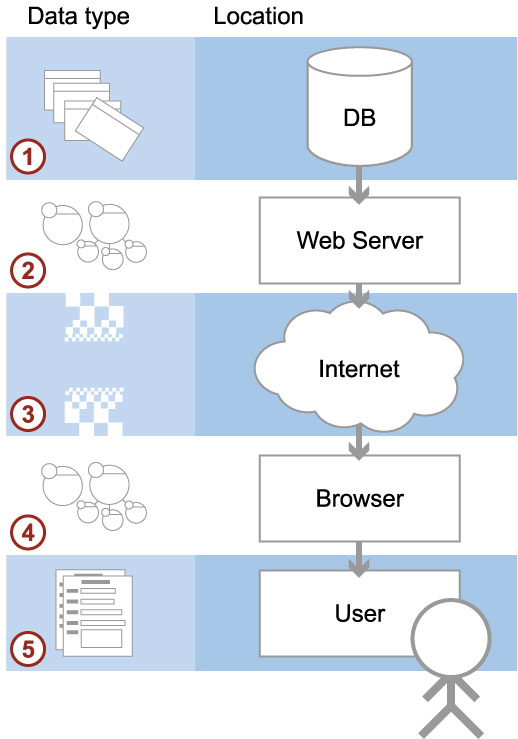
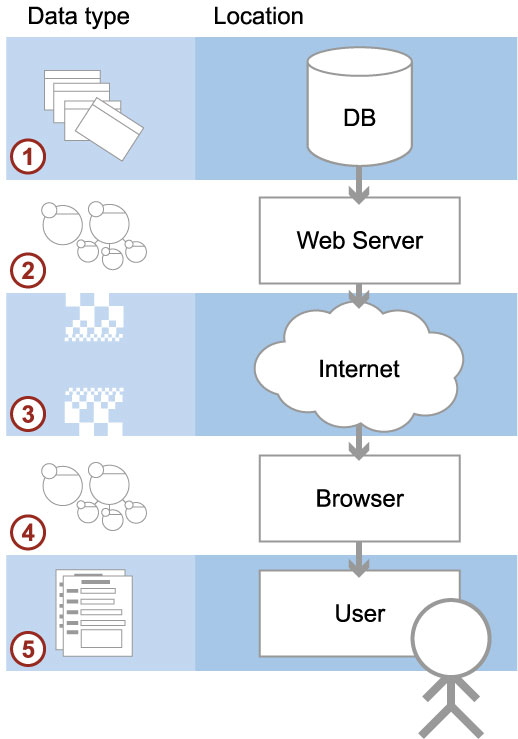
5.1.01. Databases for the Internet
- Path from DB to User
- Information flow
- Data formats (OO)
- Format transitions
- Limitations/channel
- The Future
5.1.10. load, edit, submit, act timeline
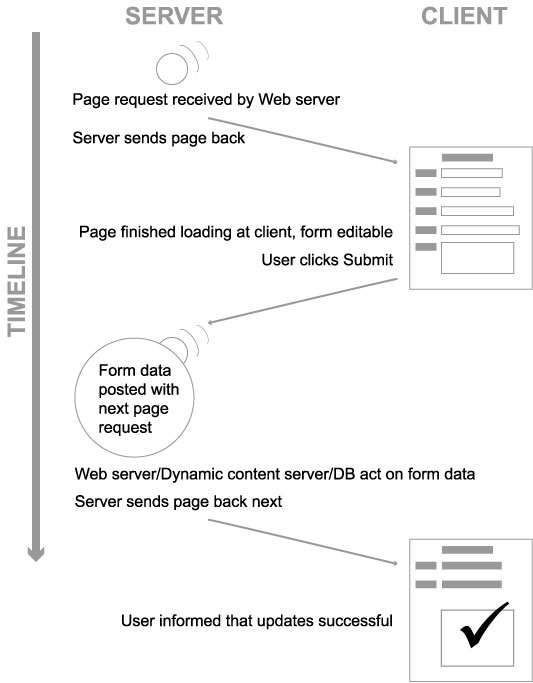
5.1.11. href click, versus form post
- Protocol stack
- Basic up-down
- Shortcuts
- Browser cache
- Web server
- assembled page cache
- php object cache
- DB optimised queries
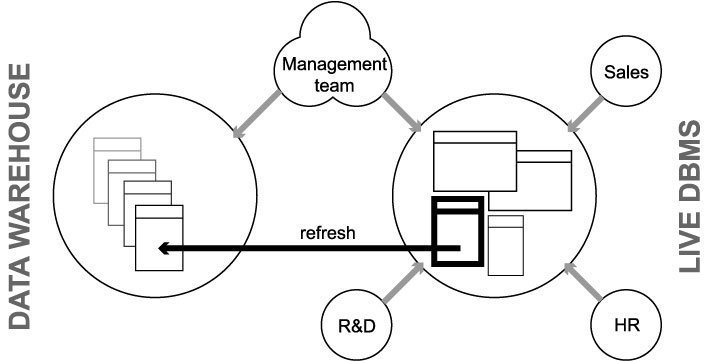
5.2.06. DB Company organisation
- By example
5.2.08. Star schemae and Hypercubes
- Data centralised in ‘fact’ table
- Referencing creates star pattern
- Dimensions as satellite tables
- Normalising creates snowflake schema
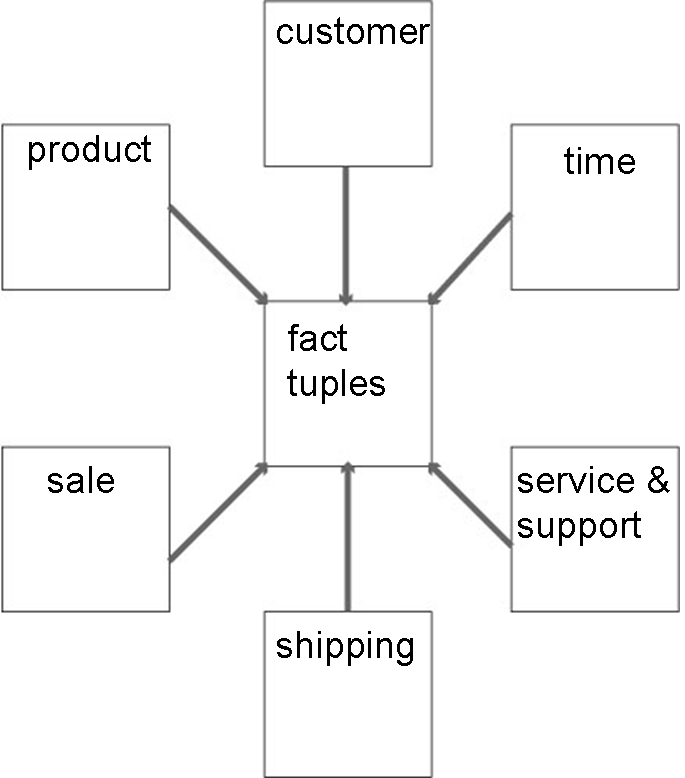
5.2.09. Hypercubes
- Hypercube is also a multi-processor topology inspired by a 4D shape
- Used by Intel’s iPSC/2
- Good at certain database operations
- e.g. Duplicate removal
- MIMD